Standard RAID levels
The standard RAID levels are a basic set of RAID configurations and employ striping, mirroring, or parity. The standard RAID levels can be modified for other benefits (see Nested RAID levels for modes like 1+0 or 0+1); there are also non-standard RAID levels, and non-RAID drive architectures, which may be offered as alternatives to RAID architectures. RAID levels and their associated data formats are standardised by SNIA in the Common RAID Disk Drive Format (DDF) standard.
Contents |
RAID 0
A RAID 0 (also known as a stripe set or striped volume) splits data evenly across two or more disks (striped) with no parity information for redundancy. RAID 0 was not one of the original RAID levels and provides no data redundancy. RAID 0 is normally used to increase performance, although it can also be used as a way to create a small number of large logical disks out of a large number of small physical ones.
A RAID 0 can be created with disks of differing sizes, but the storage space added to the array by each disk is limited to the size of the smallest disk. For example, if a 100 GB disk is striped together with a 350 GB disk, the size of the array will be 200 GB.

RAID 0 failure rate
Although RAID 0 was not specified in the original RAID paper, an idealized implementation of RAID 0 would split I/O operations into equal-sized blocks and spread them evenly across two disks. RAID 0 implementations with more than two disks are also possible, though the group reliability decreases with member size.
Reliability of a given RAID 0 set is equal to the average reliability of each disk divided by the number of disks in the set:
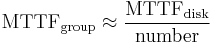
That is, reliability (as measured by mean time to failure (MTTF) or mean time between failures (MTBF)) is roughly inversely proportional to the number of members – so a set of two disks is roughly half as reliable as a single disk. If there were a probability of 5% that the disk would fail within three years, in a two disk array, that probability would be increased to 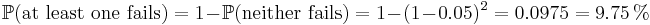 .
.
The reason for this is that the file system is distributed across all disks. When a drive fails the file system cannot cope with such a large loss of data and coherency since the data is "striped" across all drives (the data cannot be recovered without the missing disk). Data can be recovered using special tools; however, this data will be incomplete and most likely corrupt, and data recovery is typically very costly and not guaranteed.
RAID 0 performance
While the block size can technically be as small as a byte, it is almost always a multiple of the hard disk sector size of 512 bytes. This lets each drive seek independently when randomly reading or writing data on the disk. How much the drives act independently depends on the access pattern from the file system level. For reads and writes that are larger than the stripe size, such as copying files or video playback, the disks will be seeking to the same position on each disk, so the seek time of the array will be the same as that of a single drive. For reads and writes that are smaller than the stripe size, such as database access, the drives will be able to seek independently. If the sectors accessed are spread evenly between the two drives, the apparent seek time of the array will be half that of a single drive (assuming the disks in the array have identical access time characteristics). The transfer speed of the array will be the transfer speed of all the disks added together, limited only by the speed of the RAID controller. Note that these performance scenarios are in the best case with optimal access patterns.
RAID 0 is useful for setups such as large read-only NFS server where mounting many disks is time-consuming or impossible and redundancy is irrelevant.
RAID 0 is also used in some gaming systems where performance is desired and data integrity is not very important. However, real-world tests with games have shown that RAID-0 performance gains are minimal, although some desktop applications will benefit.[1][2] Another article examined these claims and concludes: "Striping does not always increase performance (in certain situations it will actually be slower than a non-RAID setup), but in most situations it will yield a significant improvement in performance." [3]
RAID 1
A RAID 1 creates an exact copy (or mirror) of a set of data on two or more disks. This is useful when read performance or reliability is more important than data storage capacity. Such an array can only be as big as the smallest member disk. A classic RAID 1 mirrored pair contains two disks (see diagram), which increases reliability geometrically over a single disk. Since each member contains a complete copy of the data, and can be addressed independently, ordinary wear-and-tear reliability is raised by the power of the number of self-contained copies.
RAID 1 failure rate
As a simplified example, consider a RAID 1 with two identical models of a disk drive with a 5% probability that the disk would fail within three years. Provided that the failures are statistically independent, then the probability of both disks failing during the three year lifetime is 0.25%. Thus, the probability of losing all data is 0.25% over a three year period if nothing is done to the array. If the first disk fails and is never replaced, then there is a 5% chance the data will be lost. If only one of the disks fails, no data would be lost. As long as a failed disk is replaced before the second disk fails, the data is safe.
However, since two identical disks are used and since their usage patterns are also identical, their failures cannot be assumed to be independent. Thus, the probability of losing all data, if the first failed disk is not replaced, may increase.
As a practical matter, in a well-managed system the above is irrelevant because the failed hard drive will not be ignored but will be replaced. The reliability of the overall system is determined by the probability the remaining drive will continue to operate through the repair period, that is the total time it takes to detect a failure, replace the failed hard drive, and for that drive to be rebuilt. If, for example, it takes one hour to replace the failed drive, the overall system reliability is defined by the probability the remaining drive will operate for one hour without failure.
While RAID 1 can be an effective protection against physical disk failure, it does not provide protection against data corruption due to viruses, accidental file changes or deletions, or any other data-specific changes. By design, any such changes will be instantly mirrored to every drive in the array segment. A virus, for example, that damages data on one drive in a RAID 1 array will damage the same data on all other drives in the array at the same time. For this reason systems using RAID 1 to protect against physical drive failure should also have a traditional data backup process in place to allow data restoration to previous points in time. As this is also the case with other RAID levels, it would seem self-evident that any system critical enough to require disk redundancy also needs the protection of reliable data backups.
RAID 1 performance
Since all the data exist in two or more copies, each with its own hardware, the read performance can go up roughly as a linear multiple of the number of copies. That is, a RAID 1 array of two drives can be reading in two different places at the same time, though not all implementations of RAID 1 do this.[4] To maximize performance benefits of RAID 1, independent disk controllers are recommended, one for each disk. Some refer to this practice as splitting or duplexing (for two disk arrays) or multiplexing (for arrays with more than two disks). When reading, both disks can be accessed independently and requested sectors can be split evenly between the disks. For the usual mirror of two disks, this would, in theory, double the transfer rate when reading. The apparent access time of the array would be half that of a single drive. Unlike RAID 0, this would be for all access patterns, as all the data are present on all the disks. In reality, the need to move the drive heads to the next block (to skip blocks already read by the other drives) can effectively mitigate speed advantages for sequential access. Read performance can be further improved by adding drives to the mirror. Many older IDE RAID 1 controllers read only from one disk in the pair, so their read performance is always that of a single disk. Some older RAID 1 implementations read both disks simultaneously to compare the data and detect errors. The error detection and correction on modern disks makes this less useful in environments requiring normal availability. When writing, the array performs like a single disk, as all mirrors must be written with the data. Note that these are best case performance scenarios with optimal access patterns.
RAID 1 has many administrative advantages. For instance, in some environments, it is possible to "split the mirror," declare one disk as inactive, do a backup of that disk, then "rebuild" the mirror. This is useful in situations where the file system must be constantly available. This requires that the application supports recovery from the image of data on the disk at the point of the mirror split. This procedure is less critical in the presence of the "snapshot" feature of some file systems, in which some space is reserved for changes, presenting a static point-in-time view of the file system. Alternatively, a new disk can be substituted so that the inactive disk can be kept in much the same way as traditional backup. To maintain redundancy during the backup process, some controllers support adding a third disk to an active pair. After the third disk rebuild completes, it is made inactive and backed up as described above.
RAID 2
A RAID 2 stripes data at the bit (rather than block) level, and uses Hamming code for error correction. The disks are synchronized by the controller to spin at the same angular orientation (they reach Index at the same time). Extremely high data transfer rates are possible. This is the only original level of RAID that is not currently used.[5][6]
The use of Hamming(7,4) code (four data bits plus three parity bits) also permits using 7 disks in RAID 2, with 4 being used for data storage and 3 being used for error correction.
RAID 2 is the only standard RAID level, other than some implementations of RAID 6, which can automatically recover accurate data from single-bit corruption in data. Other RAID levels can detect single-bit corruption in data, or can sometimes reconstruct missing data, but cannot reliably resolve contradictions between parity bits and data bits without human intervention.
(Multiple-bit corruption is possible, though extremely rare. RAID 2 can detect, but not repair, double-bit corruption.)
All hard disks eventually implemented Hamming code error correction. This made RAID 2 error correction redundant and unnecessarily complex. Like RAID 3, this level quickly became useless and is now obsolete. There are no commercial applications of RAID 2.[5][6]
RAID 3
A RAID 3 uses byte-level striping with a dedicated parity disk. RAID 3 is very rare in practice. One of the characteristics of RAID 3 is that it generally cannot service multiple requests simultaneously. This happens because any single block of data will, by definition, be spread across all members of the set and will reside in the same location. So, any I/O operation requires activity on every disk and usually requires synchronized spindles.
In our example, a request for block "A" consisting of bytes A1-A6 would require all three data disks to seek to the beginning (A1) and reply with their contents. A simultaneous request for block B would have to wait.
However, the performance characteristic of RAID 3 is very consistent, unlike that for higher RAID levels. The size of a stripe is less than the size of a sector or OS block. As a result, reading and writing accesses the entire stripe every time. The performance of the array is therefore identical to the performance of one disk in the array except for the transfer rate, which is multiplied by the number of data drives less the parity drives.
This makes it best for applications that demand the highest transfer rates in long sequential reads and writes, for example uncompressed video editing. Applications that make small reads and writes from random disk locations will get the worst performance out of this level.[6]
The requirement that all disks spin synchronously, aka lockstep, added design considerations to a level that didn't give significant advantages over other RAID levels, so it quickly became useless and is now obsolete.[5] Both RAID 3 and RAID 4 were quickly replaced by RAID 5.[7] However, this level has commercial vendors making implementations of it. It's usually implemented in hardware, and the performance issues are addressed by using large disks.[6]
RAID 4
A RAID 4 uses block-level striping with a dedicated parity disk. This allows each member of the set to act independently when only a single block is requested. If the disk controller allows it, a RAID 4 set can service multiple read requests simultaneously. RAID 4 looks similar to RAID 5 except that it does not use distributed parity, and similar to RAID 3 except that it stripes at the block level, rather than the byte level. Generally, RAID 4 is implemented with hardware support for parity calculations, and a minimum of 3 disks is required for a complete RAID 4 configuration.
In the example on the right, a read request for block A1 would be serviced by disk 0. A simultaneous read request for block B1 would have to wait, but a read request for B2 could be serviced concurrently by disk 1.
For writing, the parity disk becomes a bottleneck, as simultaneous writes to A1 and B2 would, in addition to the writes to their respective drives, also both need to write to the parity drive. In this way RAID 4 places a very high load on the parity drive in an array.
The performance of RAID 4 in this configuration can be very poor, but unlike RAID 3 it does not need synchronized spindles. However, if RAID 4 is implemented on synchronized drives and the size of a stripe is reduced below the OS block size a RAID 4 array then has the same performance pattern as a RAID 3 array.
Currently, RAID 4 is only implemented at the enterprise level by one company, NetApp. The aforementioned performance problems were solved with their proprietary Write Anywhere File Layout. WAFL is the Write Anywhere File Layout, an approach to writing data to disk locations that minimizes the conventional parity RAID write penalty. By storing system metadata (inodes, block maps, and inode maps) in the same way application data is stored, WAFL is able to write file system metadata blocks anywhere on the disk. This approach in turn allows multiple writes to be "gathered" and scheduled to the same RAID stripe—eliminating the traditional read-modify-write penalty prevalent in parity-based RAID schemes. http://partners.netapp.com/go/techontap/matl/NetApp_DNA.html
Both RAID 3 and RAID 4 were quickly replaced by RAID 5.[7]
RAID 5
A RAID 5 uses block-level striping with parity data distributed across all member disks. RAID 5 has achieved popularity because of its low cost of redundancy. This can be seen by comparing the number of drives needed to achieve a given capacity. For an array of  drives, with
drives, with 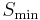 being the size of the smallest disk in the array, other RAID levels that yield redundancy give only a storage capacity of (for RAID 1), or
being the size of the smallest disk in the array, other RAID levels that yield redundancy give only a storage capacity of (for RAID 1), or 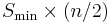 (for RAID 1+0). In RAID 5, the yield is
(for RAID 1+0). In RAID 5, the yield is 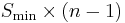 . For example, four 1 TB drives can be made into two separate 1 TB redundant arrays under RAID 1 or 2 TB under RAID 1+0, but the same four drives can be used to build a 3 TB array under RAID 5. Although RAID 5 may be implemented in a disk controller, some have hardware support for parity calculations (hardware RAID cards with onboard processors) while some use the main system processor (a form of software RAID in vendor drivers for inexpensive controllers). Many operating systems also provide software RAID support independently of the disk controller, such as Windows Dynamic Disks, Linux mdadm, or RAID-Z. A minimum of three disks is required for a complete RAID 5 configuration. In some implementations a degraded RAID 5 disk set can be made (three disk set of which only two are online), while mdadm supports a fully functional (non-degraded) RAID 5 setup with two disks - which function as a slow RAID-1, but can be expanded with further volumes.
. For example, four 1 TB drives can be made into two separate 1 TB redundant arrays under RAID 1 or 2 TB under RAID 1+0, but the same four drives can be used to build a 3 TB array under RAID 5. Although RAID 5 may be implemented in a disk controller, some have hardware support for parity calculations (hardware RAID cards with onboard processors) while some use the main system processor (a form of software RAID in vendor drivers for inexpensive controllers). Many operating systems also provide software RAID support independently of the disk controller, such as Windows Dynamic Disks, Linux mdadm, or RAID-Z. A minimum of three disks is required for a complete RAID 5 configuration. In some implementations a degraded RAID 5 disk set can be made (three disk set of which only two are online), while mdadm supports a fully functional (non-degraded) RAID 5 setup with two disks - which function as a slow RAID-1, but can be expanded with further volumes.
In the example, a read request for block A1 would be serviced by disk 0. A simultaneous read request for block B1 would have to wait, but a read request for B2 could be serviced concurrently by disk 1.
RAID 5 parity handling
A concurrent series of blocks (one on each of the disks in an array) is collectively called a stripe. If another block, or some portion thereof, is written on that same stripe, the parity block, or some portion thereof, is recalculated and rewritten. For small writes, this requires:
- Read the old data block
- Read the old parity block
- Compare the old data block with the write request. For each bit that has flipped (changed from 0 to 1, or from 1 to 0) in the data block, flip the corresponding bit in the parity block
- Write the new data block
- Write the new parity block
The disk used for the parity block is staggered from one stripe to the next, hence the term distributed parity blocks. RAID 5 writes are expensive in terms of disk operations and traffic between the disks and the controller.
The parity blocks are not read on data reads, since this would add unnecessary overhead and would diminish performance. The parity blocks are read, however, when a read of blocks in the stripe fails due to failure of any one of the disks, and the parity block in the stripe are used to reconstruct the errant sector. The CRC error is thus hidden from the main computer. Likewise, should a disk fail in the array, the parity blocks from the surviving disks are combined mathematically with the data blocks from the surviving disks to reconstruct the data from the failed drive on-the-fly.
This is sometimes called Interim Data Recovery Mode. The computer knows that a disk drive has failed, but this is only so that the operating system can notify the administrator that a drive needs replacement; applications running on the computer are unaware of the failure. Reading and writing to the drive array continues seamlessly, though with some performance degradation.
RAID 5 disk failure rate
Solid-state drives (SSDs) may present a revolutionary instead of evolutionary way of dealing with increasing RAID-5 rebuild limitations. With encouragement from many flash-SSD manufacturers, JEDEC is preparing to set standards in 2009 for measuring UBER (uncorrectable bit error rates) and "raw" bit error rates (error rates before ECC, error correction code).[8] But even the economy-class Intel X25-M SSD claims an unrecoverable error rate of 1 sector in 1015 bits and an MTBF of two million hours.[9] Ironically, the much-faster throughput of SSDs (STEC claims its enterprise-class Zeus SSDs exceed 200 times the transactional performance of today's 15k-RPM, enterprise-class HDDs)[10] suggests that a similar error rate (1 in 1015) will result a two-magnitude shortening of MTBF.
In the event of a system failure while there are active writes, the parity of a stripe may become inconsistent with the data. If this is not detected and repaired before a disk or block fails, data loss may ensue as incorrect parity will be used to reconstruct the missing block in that stripe. This potential vulnerability is sometimes known as the write hole. Battery-backed cache and similar techniques are commonly used to reduce the window of opportunity for this to occur. The same issue occurs for RAID-6.
RAID 5 performance
RAID 5 implementations suffer from poor performance when faced with a workload which includes many writes which are smaller than the capacity of a single stripe. This is because parity must be updated on each write, requiring read-modify-write sequences for both the data block and the parity block. More complex implementations may include a non-volatile write back cache to reduce the performance impact of incremental parity updates. Large writes, spanning an entire stripe width, can however be done without read-modify-write cycles for each data + parity block, by simply overwriting the parity block with the computed parity since the new data for each data block in the stripe is known in its entirety at the time of the write. This is sometimes called a full stripe write.
Random write performance is poor, especially at high concurrency levels common in large multi-user databases. The read-modify-write cycle requirement of RAID 5's parity implementation penalizes random writes by as much as an order of magnitude compared to RAID 0.[11]
The read performance of RAID 5 is almost as good as RAID 0 for the same number of disks. Except for the parity blocks, the distribution of data over the drives follows the same pattern as RAID 0. The reason RAID 5 is slightly slower is that the disks must skip over the parity blocks.
RAID 5 latency
When a disk record is randomly accessed there is a delay as the disk rotates sufficiently for the data to come under the head for processing. This delay is called Latency. On average, a single disk will need to rotate 1/2 revolution. Thus, for a 7200 RPM disk the average latency is 4.2 milliseconds. In RAID 5 arrays all the disks must be accessed so the latency can become a significant factor. In a RAID 5 array, with n randomly oriented disks, the average latency becomes 1-(2-n) revolutions. In order to mitigate this problem, well designed RAID systems will synchronize the angular orientation of their disks. In this case the random nature of the angular displacements goes away, the average latency returns to 1/2 revolution, and a savings of up to 50% in latency is achieved. Since Solid State Disks do not rotate, their latency does not follow this model.
| Number of Disks | Average Randomly Oriented Latency (Revolutions) |
| 1 | 0.500 |
| 2 | 0.750 |
| 3 | 0.875 |
| 4 | 0.938 |
| 5 | 0.969 |
| 6 | 0.984 |
| 7 | 0.992 |
| 8 | 0.996 |
RAID 5 usable size
Parity data uses up the capacity of one drive in the array. (This can be seen by comparing it with RAID 4: RAID 5 distributes the parity data across the disks, while RAID 4 centralizes it on one disk, but the amount of parity data is the same.) If the drives vary in capacity, the smallest one sets the limit. Therefore, the usable capacity of a RAID 5 array is 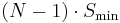 , where
, where 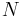 is the total number of drives in the array and is the capacity of the smallest drive in the array.
is the total number of drives in the array and is the capacity of the smallest drive in the array.
The number of hard disks that can belong to a single array is limited only by the capacity of the storage controller in hardware implementations, or by the OS in software RAID. One caveat is that unlike RAID 1, as the number of disks in an array increases, the probability of data loss due to multiple drive failures also increases. This is because there is a reduced ratio of "losable" drives (the number of drives which may fail before data is lost) to total drives.
RAID 6
Redundancy and data loss recovery capability
RAID 6 extends RAID 5 by adding an additional parity block; thus it uses block-level striping with two parity blocks distributed across all member disks.
Performance (speed)
RAID 6 does not have a performance penalty for read operations, but it does have a performance penalty on write operations because of the overhead associated with parity calculations. Performance varies greatly depending on how RAID 6 is implemented in the manufacturer's storage architecture – in software, firmware or by using firmware and specialized ASICs for intensive parity calculations. It can be as fast as a RAID-5 system with one fewer drive (same number of data drives).[12]
Efficiency (potential waste of storage)
RAID 6 is no more space inefficient than RAID 5 with a hot spare drive when used with a small number of drives, but as arrays become bigger and have more drives, the loss in storage capacity becomes less important and the probability of data loss is greater. RAID 6 provides protection against data loss during an array rebuild, when a second drive is lost, a bad block read is encountered, or when a human operator accidentally removes and replaces the wrong disk drive when attempting to replace a failed drive.
The usable capacity of a RAID 6 array is 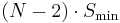 , where is the total number of drives in the array and is the capacity of the smallest drive in the array.
, where is the total number of drives in the array and is the capacity of the smallest drive in the array.
Implementation
According to the Storage Networking Industry Association (SNIA), the definition of RAID 6 is: "Any form of RAID that can continue to execute read and write requests to all of a RAID array's virtual disks in the presence of any two concurrent disk failures. Several methods, including dual check data computations (parity and Reed-Solomon), orthogonal dual parity check data and diagonal parity, have been used to implement RAID Level 6."[13]
Computing parity
Two different syndromes need to be computed in order to allow the loss of any two drives. One of them, P can be the simple XOR of the data across the stripes, as with RAID 5. A second, independent syndrome is more complicated and requires the assistance of field theory.
To deal with this, the Galois field 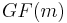 is introduced with
is introduced with 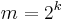 , where
, where ![GF(m) \cong F_2[x]/(p(x))](/2012-wikipedia_en_all_nopic_01_2012/I/837e456c5f5cae0a8b6820c3758132c5.png) for a suitable irreducible polynomial
for a suitable irreducible polynomial 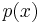 of degree
of degree  . A chunk of data can be written as
. A chunk of data can be written as 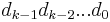 in base 2 where each
in base 2 where each 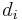 is either 0 or 1. This is chosen to correspond with the element
is either 0 or 1. This is chosen to correspond with the element 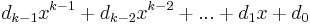 in the Galois field. Let
in the Galois field. Let 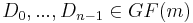 correspond to the stripes of data across hard drives encoded as field elements in this manner (in practice they would probably be broken into byte-sized chunks). If
correspond to the stripes of data across hard drives encoded as field elements in this manner (in practice they would probably be broken into byte-sized chunks). If 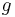 is some generator of the field and
is some generator of the field and  denotes addition in the field while concatenation denotes multiplication, then
denotes addition in the field while concatenation denotes multiplication, then 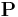 and
and 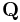 may be computed as follows ( denotes the number of data disks):
may be computed as follows ( denotes the number of data disks):
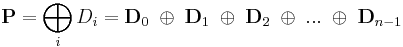
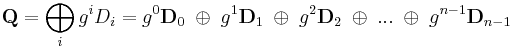
For a computer scientist, a good way to think about this is that is a bitwise XOR operator and 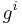 is the action of a linear feedback shift register on a chunk of data. Thus, in the formula above,[14] the calculation of P is just the XOR of each stripe. This is because addition in any characteristic two finite field reduces to the XOR operation. The computation of Q is the XOR of a shifted version of each stripe.
is the action of a linear feedback shift register on a chunk of data. Thus, in the formula above,[14] the calculation of P is just the XOR of each stripe. This is because addition in any characteristic two finite field reduces to the XOR operation. The computation of Q is the XOR of a shifted version of each stripe.
Mathematically, the generator is an element of the field such that is different for each nonnegative  satisfying
satisfying 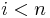 .
.
If one data drive is lost, the data can be recomputed from P just like with RAID 5. If two data drives are lost or the drive containing P is lost the data can be recovered from P and Q using a more complex process. Working out the details is extremely hard with field theory, and the lack of explanation here isn't making it any easier. Suppose that 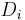 and
and 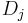 are the lost values with
are the lost values with 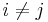 . Using the other values of
. Using the other values of 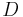 , constants
, constants  and
and 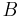 may be found so that
may be found so that 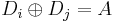 and
and 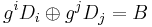 . Multiplying both sides of the latter equation by
. Multiplying both sides of the latter equation by 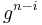 and adding to the former equation yields
and adding to the former equation yields 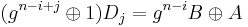 and thus a solution for which may be used to compute .
and thus a solution for which may be used to compute .
The computation of Q is CPU intensive compared to the simplicity of P. Thus, a RAID 6 implemented in software will have a more significant effect on system performance, and a hardware solution will be more complex.
Non-standard RAID levels and non-RAID drive architectures
There are other RAID levels that are promoted by individual vendors, but not generally standardized. The non-standard RAID levels 5E, 5EE and 6E extend RAID 5 and 6 with hot-spare drives.
Other non-standard RAID levels include:
- RAID 1.5,
- RAID 7 (a hardware-supported, proprietary RAID developed by Storage Computer Corp. of Nashua, NH),
- RAID-DP,
- RAID S or parity RAID,
- Matrix RAID,
- RAID-K,
- RAID-Z,
- RAIDn,
- Linux MD RAID 10,
- IBM ServeRAID 1E,
- nunRAID,
- ineo Complex RAID, and
- Drobo BeyondRAID.
There are also non-RAID drive architectures, which are referred to by similar acronyms, notably SLED, Just a Bunch of Disks, SPAN/BIG, and MAID.
See also
References
- ^ "Western Digital's Raptors in RAID-0: Are two drives better than one?". AnandTech. July 1, 2004. http://www.anandtech.com/storage/showdoc.aspx?i=2101. Retrieved 2007-11-24.
- ^ "Hitachi Deskstar 7K1000: Two Terabyte RAID Redux". AnandTech. April 23, 2007. http://www.anandtech.com/storage/showdoc.aspx?i=2974. Retrieved 2007-11-24.
- ^ "RAID 0: Hype or blessing?". Tweakers.net. August 7, 2004. http://tweakers.net/reviews/515/1/raid-0-hype-or-blessing-pagina-1.html. Retrieved 2008-07-23.
- ^ "Mac OS X, Mac OS X Server: How to Use Apple-Supplied RAID Software". Apple.com. http://docs.info.apple.com/article.html?artnum=106594. Retrieved 2007-11-24.
- ^ a b c Derek Vadala (2003). Managing RAID on Linux. O'Reilly Series (illustrated ed.). O'Reilly. p. 6. ISBN 1565927303, 9781565927308. http://books.google.com/?id=RM4tahggCVcC&pg=PA6&dq=raid+2+implementation#v=onepage&q=raid%202%20implementation.
- ^ a b c d Evan Marcus, Hal Stern (2003). Blueprints for high availability (2, illustrated ed.). John Wiley and Sons. p. 167. ISBN 0471430269, 9780471430261. http://books.google.com/?id=D_jYqFoJVEAC&pg=RA2-PA167&dq=raid+2+implementation#v=onepage&q=raid%202%20implementation.
- ^ a b Michael Meyers, Scott Jernigan (2003). Mike Meyers' A+ Guide to Managing and Troubleshooting PCs (illustrated ed.). McGraw-Hill Professional. p. 321. ISBN 0072231467, 9780072231465. http://books.google.com/?id=9vfQKUT_BjgC&pg=PT348&dq=raid+2+implementation#v=onepage&q=raid%202%20implementation.
- ^ Shilov, Anton (November 20, 2008). "JEDEC to Set Solid State Drive Standards in 2009". X-bit labs. http://www.xbitlabs.com/news/storage/display/20081120042457_JEDEC_to_Set_Solid_State_Drive_Standards_in_2009.html. Retrieved 2009-03-24.
- ^ "Intel X18-M/X25-M SATA Solid State Drive (SSDSA1MH080G2, SSDSA2MH080G2, SSDSA1MH160G2, SSDSA2MH160G2) Product Manual" (PDF). Intel Corporation. July 2009. pp. 1. http://download.intel.com/design/flash/nand/mainstream/322296.pdf. Retrieved 2009-07-23.
- ^ "ZeusIOPS Solid State Drive". STEC, Inc.. 2005-04-02. http://www.stec-inc.com/product/zeusiops.php. Retrieved 2009-03-24.
- ^ Cary Millsap (21 August 1996) (PDF). Configuring Oracle Server for VLDB. http://oreilly.com/catalog/oressentials2/chapter/vldb1.pdf.
- ^ Rickard E. Faith (13 May 2009). A Comparison of Software RAID Types. http://alephnull.com/benchmarks/sata2009/raidtype.html.
- ^ "Dictionary R". Storage Networking Industry Association. http://www.snia.org/education/dictionary/r/. Retrieved 2007-11-24.
- ^ Anvin, H. Peter (21 May 2009). "The mathematics of RAID-6". http://www.kernel.org/pub/linux/kernel/people/hpa/raid6.pdf. Retrieved November 4, 2009.
External links
- RAID Calculator for Standard RAID Levels and Other RAID Tools
- Tutorial on "RAID 6 Essentials — reduced performance or not?" - Requires Flash.
- IBM summary on RAID levels
- RAID 5 Parity explanation and checking tool.
- Dell animations and details on RAID levels 0, 1, 5
- The Open-E Blog. "How does RAID 5 work? The Shortest and Easiest explanation ever!"